Legacy Modernisation Playbook
Problem Statement
Many organisations have Legacy Software Applications/Systems/Processes characterised by more than one of the following:
- No available documentation or code
- Hardware platform is probably outdated/costly
- Few or no people have a deep technical understanding of the system
- The lack of system flexibility is holding back the business
- This leads to the risk of change being seen as unacceptably high
Many companies “accumulate” legacy systems as they grow – this is often in the form of data in spreadsheets and the processes that are used (and stored in peoples heads) in order to manage them.
The common approach is to cobble together some partial replacement, or copy what is believed the system does. Often, this involves trying to write it down first as a requirements document, build the copy, then replace it “big bang” style (with your fingers crossed !).
Alternatively, the code can be converted to some other language (e.g. COBOL to Java), but this often then leaves you with a nightmare of machine converted code that is often harder to maintain than what you started with, and one of the primary reasons for replacement is often that the system needs alteration in some way for compliance/regulation or business change.
But there is a much better way…
The Rulevolution Approach to Legacy Modernisation
This Legacy Modernisation approach is applicable whether this is a batch, inline (straight through) processing or screen based environment being replaced, although obviously some of the finer details may differ;
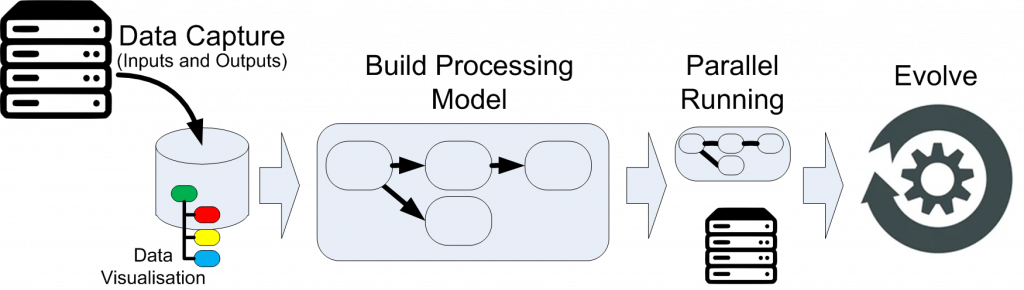
- First data is captured from the old system (or read from a database) – volume does not matter, ideally a wide range of examples should be found. Rulevolution allows this to be visualised in a structured manner known as a knowledge (or conceptual) graph
- Consulting with existing personnel, the processes are replicated within the Rulevolution system (often bugs are found, and informed decisions will need to be made whether to replicate the bugs for the sake of downwind systems, or to correct them)
- Once believed to complete, the processes can be run against larger datasets, differences can be isolated, answers found (sometimes debugging existing code may be required if available). The process can then be refined and this step repeated
- With the processes replicated, a period of parallel running is recommended to confirm the duplication
- The processes can now be evolved to the new requirements (where required) in a controlled and incremental manner
Via this route a thorough replication of the existing system can be proven (more than in other approaches), a new system is available for running in a new environment quickly (e.g. Cloud), and the risk to the organisation quickly reduced. Incremental, controlled and version controlled adjustments can then be made to evolve the desired behaviour to the final required state.
Advantages
- Actual examples are a much better way to extract tacit knowledge from the head of the expert users (who have an idea of what the system achieves), rather than asking them to write it down
- The replicated processes can be “used as is” to reduce costs immediately
- The replicated processes can be tested against (or used to test) any future system
- Running the replicated processes in parallel for a period, reduces the risk of future issues, boundary conditions can be used to flag “new”/unseen data to allow checking, and thus not “to just process it blindly”
- System evolution is then down to incremental (and controllable) steps thus removing the risks of a “big-bang” implementation
- At any point the requirements can be exported as a document, thus you are never exposed to the risk of an unknown system or lock-in
- You may also be able to use one of our Solution Templates to kickstart development